[dropcap3]G[/dropcap3]ioventù svogliata, un po’ narcisista e dedita solo all’ozio? Incapace di sfidare il mondo del lavoro con piglio deciso in nome delle proprie idee e dei propri progetti?
Si potrebbe sostenere il contrario, considerando l’ingegno e l’iniziativa di chi si affida al crowdfounding, una pratica di microfinanziamento erogato “dal basso” in cui chiunque può utilizzare il proprio denaro per sponsorizzare progetti proposti da altri.
Proprio per andare incontro a tale intraprendenza, nel 2009, è nata la piattaforma Kickstarter, che ha la sua base nel Lower East Side di Manhattan ed è stata lanciata dagli ormai celebri Perry Chen, Yancey Strickler e Charles Adler.
Solo dopo un anno dal suo avvio fu nominata dalla rivista TIME una delle “Migliori invenzioni del 2010” e, in seguito, “Miglior sito web del 2011”.
![]() La piattaforma è specializzata nella raccolta di fondi attraverso il web, e funziona attraverso l’incontro tra la domanda di sovvenzioni da parte di giovani imprenditori (con un sogno nel cassetto) e l’offerta di finanziamento da parte di chi, seppure estraneo, è interessato a partecipare economicamente alla startup del progetto o dell’idea proposti.
La piattaforma è specializzata nella raccolta di fondi attraverso il web, e funziona attraverso l’incontro tra la domanda di sovvenzioni da parte di giovani imprenditori (con un sogno nel cassetto) e l’offerta di finanziamento da parte di chi, seppure estraneo, è interessato a partecipare economicamente alla startup del progetto o dell’idea proposti.
Un esempio? Ce ne sono in realtà tanti, alcuni leggendari. Come lo smartwatch Pebble o il frigorifero Coolest Cooler, o ancora le carte da gioco Exploding Kittens… tutte “storie” a lieto fine che, nel loro complesso, hanno racimolato più di 43 milioni di dollari, e che hanno narrato, in questi anni, le potenzialità del crowdfunding, tutte accomunate dalla presenza di un comune Eroe: la piattaforma Kickstarter.
La compagnia, infatti, in poco meno di sei anni, ha accompagnato e dato il via alla produzione di oltre 86.000 fra progetti artistici, giochi, iniziative giornalistiche, dischi, abiti, fumetti, alimenti, prodotti di design originali e innovativi, consentendo loro di raggiungere – e a volte superare – l’obiettivo previsto. Questo, grazie agli 8,8 milioni di persone che, in tutto il pianeta, hanno raccolto finanziamenti pari a 1,6 miliardi di dollari.
Non tutti i paesi hanno però potuto disporre in questi anni di tale grande opportunità: l’Italia era purtroppo uno di quelli esclusi. Si poteva cioè partecipare al decollo dei progetti altrui, ma non proporli per la propria raccolta di fondi.
Ora, dopo una lunga attesa, Kickstarter ha finalmente esteso il proprio benefico dominio anche al nostro paese, che è diventato il tredicesimo nel mondo in cui inventori, visionari e creativi sono autorizzati a lanciare una campagna di finanziamento.
Visti gli ottimi risultati ottenuti in altri stati europei come Francia, Germania, Spagna e Regno Unito (divenuto il secondo mercato per entità di investimenti), Chen, Strickler e Adler attendono buoni riscontri anche in Italia, visto che gli italiani stessi, nel corso del 2014, hanno sostenuto progetti affidati alla piattaforma da tutto il mondo per un totale di 3 milioni di dollari.
È utile sottolinare che non verrà aperto un sito a parte: i progetti proposti dagli imprenditori italiani entreranno a far parte della community mondiale. Questa infatti è considerata la strategia migliore, se si pensa che il 40% dei fondi è versato da finanziatori che non abitano negli Stati Uniti.
I contenuti proposti potranno essere inseriti e promossi nel portale sia in italiano che inglese o in entrambe le lingue, e allo stesso modo sarà per i video, cui sarà possibile abbinare sottotitoli in lingue diverse.
Che altro aggiungere? C’è bisogno di sogni, in questo mondo, soprattutto di quelli che si possono realizzare, e Kickstarter sa come farlo.
Ora sta a noi, partecipare. Sia per proporre le nostre idee che per sostenere quelle degli altri. La sfida è aperta!
[boxed_content type=”whitestroke” custom_bg_colour=”#e0e0e0″ custom_text_colour=”#000000″ pb_margin_bottom=”yes” width=”1/1″ el_position=”first last”]

– Wired.it
– Hwupgrade.it
– Hansa.it
– Corriere.it
[/boxed_content]
[dropcap3]A[/dropcap3] volte un contrattempo o un ritardo aprono possibilità insperate, e il tempo di una vacanza si trasforma in un’impresa tanto complessa e ambiziosa quanto vitale ed entusiasmante.
E’ quanto avvenuto alla fine del 2014, tra Reggio Emilia e il Salento, passando per Bari, Parma, Genova e poi Modena, Foggia, Ferrara e il Piemonte.
Di cosa si tratta? Di EduOpen, un grande balzo in avanti nel settore della formazione avanzata a distanza che in un sol colpo colma anni di ritardo, mettendo finalmente l’Italia in pari con gli altri pesi europei.
Ma facciamo un passo indietro, alle sorgenti di questa storia esemplare, dal sound tipicamente italiano, in cui la creatività e l’ingegno sono capaci di sorgere – e risorgere – nei modi e nei tempi più imprevedibili.
Sono i giorni di Natale 2014, e il Ministero dell’Istruzione, dell’Università e della Ricerca proroga al 28 dicembre il bando annuale per il finanziamento di progetti innovativi, anziché rispettare la tradizionale scadenza di ottobre.
Alcuni professori universitari degli Atenei di Ferrara, Foggia, Genova, Modena e Reggio Emilia, Parma, del Piemonte Orientale e del Salento, del Politecnico e dell’Aldo Moro di Bari, decidono – a Università chiuse, e alcuni di loro già in vacanza in varie parti dell’Italia – decidono tra Natale e Santo Stefano di approfittare di questa dilazione per presentare in “volata” un progetto che sta loro a cuore da tempo: una piattaforma italiana federata per l’erogazione di corsi in modalità OpenLearning, sul modello dei MOOCs.
Nei pochi giorni a disposizione, e chiaramente a distanza, chi al telefono, chi alla scrivania e chi al pc, il progetto si materializza in tutta la sua semplice complessità.
Più difficile è raccogliere le firme di tutti, indispensabili per la validità della richiesta.
Il tempo stringe, i giorni passano, ma il patto è siglato, e il progetto – che già era ben impresso nelle loro menti da tempo – è nero su bianco, con tanto di firme e controfirme.
Per la prima volta in Italia nove Atenei si raccolgono attorno un progetto comune, partecipano al bando e…
Vincono, è chiaro. Tutti noi, anche adesso, nel leggere la loro impresa dietro le quinte, ce lo aspettavamo. Ma il risultato non era per niente scontato.
La competizione era agguerrita, la burocrazia temibile come sempre, l’imprevisto dietro a ogni angolo. Vincono. Anche se il fondo economico ottenuto – a differenza di quanto richiesto dal gruppo di Atenei – è risicato: 100.000 euro una tantum, che bastano giusto per le spese.
Ma i nove Cavalieri e Cavaliere della formazione digitale non si fanno certamente fermare sul più bello. Anzi, sono già partiti, lancia in resta.
In aprile, a Modena e alla presenza dei Rettori degli atenei coinvolti o dei loro delegati, i nostri Eroi hanno proceduto alla sigla del protocollo d’intesa triennale, ufficializzando così il progetto. Tra questi, ne abbiamo intercettato uno al volo e lo abbiamo intervistato, rigorosamente via Skype.
E’ il professor Tommaso Minerva (un nome, un destino, vista l’etimologia del suo cognome), Professore Ordinario e Direttore del Centro e-Learning di Ateneo presso l’Università di Modena e Reggio Emilia nonché Presidente della Società italiana di e-Learning (Sle – L).
Ha risposto alle nostre domande, e il suo racconto ci ha emozionato. E la parte più bella di questa storia, proprio perché concreta e reale, è il resoconto di cosa propone e cosa proporrà EduOpen, come ci ha spiegato punto per punto nell’intervista che segue.
La prima domanda, professor Minerva: cosa sono i MOOCs?
Sono dei corsi brevi offerti in modalità telematica, inscritti nella tradizione più ampia delle cosiddette OER (Open Educational Resources). Consentono di seguire percorsi formativi di alta qualità a distanza e di acquisire, se richiesto, attestati di frequenza o crediti formativi universitari.
Dal punto di vista economico, se la necessità dell’utente è solo quella di frequenza e apprendimento, non dovrà sostenere alcun costo. Se invece gli occorrerà una certificazione di acquisizione di questa competenza, magari per motivi professionali, dopo aver sostenuto l’esame potrà chiederne l’attestazione, dietro il versamento di poche decine di euro per le spese di segreteria.
Se infine tale studio sarà finalizzato al conseguimento di una vera e propria laurea, allora ogni esame sostenuto prevederà un costo di “ufficializzazione”, che comunque non supererà le poche centinaia di euro ciascuno.
Esisteva già qualcosa di simile in Italia, prima del vostro progetto?
Diversi atenei italiani in questi anni si sono già cimentati nella realizzazione di corsi aperti completamente gratuiti o che prevedono il pagamento di piccole somme finalizzate unicamente alla certificazione finale degli apprendimenti.
Non esisteva tuttavia ancora una piattaforma che aggregasse diverse università, né si è mai dato vita a un modello di progettazione ed erogazione strutturato, organizzato e condiviso.
Ci sono altri esempi di network simili in Europa?
Sì, in moltissimi dei Paesi europei, tra cui la Francia, la Spagna, l’Inghilterra, la Germania. Nati da istanze molto differenti a seconda della nazione interessata, a volte a seguito di un incentivo statale altre volte in base a richieste “dal basso”, i MOOCs sono attivi in Europa (e oltreoceano) già da tempo, ed hanno ampiamente dimostrato la propria efficacia, realizzando modelli di fatto a cui attingere e da seguire anche nella nostra “impresa”.
In base a quali requisiti o sentiment comuni si sono riuniti i nove Atenei interessati dal progetto di OpenLearning?
Come ho già raccontato il progetto è nato quasi per caso, e si è potuto concretizzare a partire da due fattori principali.
Innanzitutto la conoscenza personale tra i vari referenti di Ateneo, che ci ha consentito una partenza informale e veloce basata sull’entusiasmo di condividere una idea comune. In secondo luogo le caratteristiche strutturali dei nove atenei coinvolti. Si tratta di realtà di piccole-medie dimensioni in cui esistono legami e pratiche di reciprocità e collaborazione interne ampiamente condivise, che ci hanno consentito una maggiore flessibilità di azione e un minore impatto della cosiddetta burocrazia procedurale. Come ogni progetto innovativo, anche il nostro è partito dunque da singoli individui che si sono messi insieme per perseguire un destino comune.
Si può dire che in questo modo si infrangono molti degli stereotipi legati al tema dello studio, della ricerca e della formazione?
Sicuramente. Gli stereotipi che in questo progetto saltano sono molteplici, e la portata innovativa del progetto, nel panorama italiano, è notevole a mio parere.
Il modello del progetto si basa innanzitutto su una possibilità di personalizzazione del proprio percorso di studi o comunque formativo: ciascun ateneo infatti si specializzerà in un proprio ambito di “eccellenza”, e lo studente potrà scegliere in piena autonomia quali corsi frequentare.
Credito dopo credito, esame dopo esame, alla fine del percorso di studi lo studente potrà scegliere la disciplina più attinente al proprio ciclo di studi e, dopo aver concordato eventuali esami integrativi con l’ateneo prescelto per la propria laurea, potrà formalizzarla secondo il regolamento previsto normalmente.
È evidente che in questo modo rendiamo fruibile, da qualunque postazione fisica, l’accesso a conoscenze di cui chiunque può disporre on demand, sulla base dei propri interessi o necessità, anche personali.
Si tratta in effetti di una vera e propria rivoluzione, soprattutto per gli standard italiani! Quali sono quindi i prossimi step previsti del progetto?
Come si può vedere dal nostro sito abbiamo tracciato una serie di tappe ben precise.
Entro fine anno partiamo ufficialmente con l’erogazione dei corsi: ogni ateneo si è impegnato per allora a produrre in questa modalità 9 crediti formativi, suddivisi in più corsi. La finalità è quella di creare nel tempo altrettanti percorsi di studi, specializzando ciascun Ateneo in un proprio settore di eccellenza.
Siamo già tutti all’opera a pieno regime, e senz’altro speriamo di raggiungere il traguardo nei tempi previsti. Sempre sul sito, chi vorrà, potrà iscriversi per avere gli aggiornamenti in diretta sia sul nostro percorso che sui corsi di mano in mano attivati.
E’ molto chiaro il range di vantaggi per lo studente di una modalità di formazione di questo tipo. Ma qual è il valore aggiunto per un docente e, su più larga scala, per un ateneo che vi partecipa?
Intanto posso dire che, a livello personale, il primo valore aggiunto che mi viene in mente è semplice: mi piace il mio lavoro, e mi diverto tantissimo nel farlo. Lo stesso vale per i miei compagni di avventura. Innegabilmente, poi, è una questione di “orizzonte” che si allarga, con tutte le smisurate – ma misurabili – possibilità che una rete di questo tipo può dispiegare. Infine stiamo parlando di un tema che mi sta molto a cuore: la ricerca e l’innovazione.
Unendo le forze e ottimizzando procedure e pratiche, le risorse investite si possono mettere a regime, consentendoci così di investire di più ma soprattutto meglio nella ricerca, avanzando passo dopo passo, o almeno provando a farlo.
La nostra speranza, in questo caso, è che il progetto abbia una sua forza e valore tali da riuscire ad avanzare presto sulle proprie gambe, grazie ai tanti bisogni che può andare a coprire. Pensiamo ad esempio alla questione dell’aggiornamento permanente, che riguarda ormai ciascuno di noi. O anche agli interessi personali, che possono riguardare materie altrimenti inaccessibili dal punto di vista logistico o contingente. O ancora alle necessità cui ci vincola la vita quotidiana… Basti pensare al settore della salute. Che valore si può dare alla possibilità di documentarsi direttamente e con basi scientifiche solide, da un esperto di una determinata patologia, su quali sono le due caratteristiche, gli approcci diagnostici e terapeutici? Certamente non per curarsi da soli (è sempre necessario affidarsi a un esperto qualificato!), ma per essere consapevoli e informati, questo sì. In ognuno di questi esempi, gratuitamente e da casa propria, si potrà dunque attingere a un sapere altamente qualificato in un rapporto quasi di uno a uno, cosa un tempo inimmaginabile. Ecco: essere attore di questo processo penso non abbia prezzo.
Siamo pienamente d’accordo! E a proposito di attori e spettatori: come possiamo noi, dall’esterno di questo processo, renderci utili al progetto?
Uscendo dal ruolo di semplici osservatori e facendone parte concretamente.
Attraverso la semplice divulgazione o la partecipazione indiretta. O anche soltanto facendo il tifo per noi. Perché la forza di questo progetto è rappresentato dal suo nome: EduOpen. Ovvero apertura ed educazione. Reciproca, continua e auto-generativa.
Grazie professor Minerva. Senz’altro parteciperemo attivamente a questa avventura appena iniziata che mostra fin da ora tutto il suo potenziale innovativo.
Eccoci qui, allora, alla fine dell’intervista. Da parte nostra, vi terremo costantemente aggiornati sugli sviluppi di questa impresa memorabile, che nel frattempo ha proseguito il suo corso. Ai primi di giugno, infatti, anche l’Università degli Studi di Milano Bicocca ha aderito al Network del Progetto EduOpen, e, sempre a metà del mese, si è tenuto a Reggio Emilia un incontro tecnico molto importante tra gli Instructional Designer, CINECA e Consorzio GARR, per definire le linee guida di progettazione e creazione dei corsi e dei percorsi formativi. In qualità di osservatori interessati c’erano anche gli atenei di Venezia Ca’ Foscari, di Urbino, di Trieste e del Politecnica delle Marche.
La “rete” sta insomma crescendo, e diventa giorno dopo giorno sempre più attiva.
Perché la “gratuità” – ben lontana dall’essere buonista o semplicemente volontaristica – ha un’ambizione altrettanto utile e pressoché sterminata: guardare al futuro anziché al presente, nell’idea di una reciprocità capace di passare ogni confine.
Così che quanto seminato oggi si possa raccogliere non solo domani, ma dopodomani, e dopo dopodomani. Qui e altrove. Esiste forse ambizione più grande della universalità? A presto dunque, su questi schermi. Anzi, sui vostri!
[boxed_content type=”whitestroke” custom_bg_colour=”#e0e0e0″ custom_text_colour=”#000000″ pb_margin_bottom=”yes” width=”1/1″ el_position=”first last”]
Contatti EduOpen
[highlight]Web[/highlight]
www.eduopen.it
[/boxed_content]
Maps Group parteciperà al Global City Team Challenge (GCTC) di Washington (Stand 59), presentando il Progetto ROSE (Realtime Operational Smartgrid for Europe) nel settore della produzione, distribuzione e dispacciamento dell’Energia. Il Progetto ROSE fa uso dell’innovativo Motore Semantico real-time Iasmine, in un approccio di Operational Intelligence e Social Intelligence.
 Il Global City Team Challenge (GCTC) è un network di team progettuali o ‘action cluster’, che lavorano su applicazioni innovative delle tecnologie di Internet of Things (IoT) in contesti di smart cities e smart communities.
Il Global City Team Challenge (GCTC) è un network di team progettuali o ‘action cluster’, che lavorano su applicazioni innovative delle tecnologie di Internet of Things (IoT) in contesti di smart cities e smart communities.
Il National Institute of Standards and Technology (NIST) e US Ignite, in collaborazione con Department of Transportation (DoT), National Science Foundation (NSF), International Trade Administration (ITA), Department of Health and Human Services (HHS), Department of Energy (DoE), hanno creato il Global City Teams Challenge allo scopo di incrementare l’applicazione della ricerca più avanzata per affrontare le maggiori sfide che le città moderne sono costrette ad affrontare.
La GCTC mira a supportare le comunità a lavorare insieme per affrontare temi che spaziano dai trasporti alla pubblica sicurezza, da educazione e lavoro alla sanità, dai materiali avanzati all’energia. Il NIST vuole coinvolgere le comunità e gli innovatori nella creazione di team che possano sostenere la diffusione delle smart cities, traendo vantaggio da network tecnologici che permettano di gestire in modo più efficiente le risorse e migliorare la qualità della vita. Gli ‘Action clusters’, composti da rappresentanti delle amministrazioni locali, organizzazioni no-profit e private, si formano tramite gli eventi del NIST e di US Ignite, nonché mediante il sito web di quest’ultimo. I team lavoreranno insieme per costruire, implementare o testare applicazioni IoT.
La GCTC è un’eredità della Smart America, un’iniziativa lanciata dal NIST nel 2013-2014, alla quale hanno partecipato più di 100 organizzazioni raggruppate in 24 team. A valle di tale fruttuosa esperienza, è stata lanciata la GCTC a fine Settembre del 2014. Si è trattato di un grande successo che ha visto più di 350 partecipanti, anche da remoto.
L’Agenda del GCTC Festival, che si terrà a Washington i prossimi 1-2 Giugno 2015 prevede numerosi momenti di interesse:
– Una visita speciale del Re Willem-Alexander e della Regina Máxima del Regno d’Olanda;
– Interventi di intellettuali e rappresentanti di agenzie del Governo degli Stati Uniti;
– Presentazioni ed esibizioni di oltre 45 team, incluse città quali New York (NY), Chicago (IL), San Francisco (CA), Portland (OR), Austin (TX), Charlotte (NC), Chattanooga (TN), Columbus (OH), Flagstaff (AZ), Genova (Italy), Kansas City (MO), e Washington (DC)

Sara Magri (Gestione Risorse Umane) racconta l’esperienza all’ultima edizione dell’appuntamento dedicato all’incontro tra mondo dell’Università e imprese del settore ICT
“Un’esperienza positiva, con un’ottima organizzazione e una grande affluenza”. Con queste parole Sara Magri (Gestione Risorse Umane, Maps Group) ha commentato la recente partecipazione all’ICT Day 2015 ospitato dalla facoltà di Ingegneria dell’Università di Parma, organizzato da Università degli Studi di Parma e promosso dalle Aziende del Comparto Informatico associate all’Unione Parmense degli Industriali. Sara ha partecipato all’evento rappresentando Maps Group e, meglio di chiunque altro, può valutare lo svolgimento di questo appuntamento pensato per creare occasioni di collaborazione tra mondo dell’università e imprese del territorio. “Credo che sia stata un’edizione notevole sotto molti punti di vista – ha detto Sara Magri – innanzitutto per la partecipazione spontanea degli studenti. Abbiamo registrato un’affluenza consistente sia da parte degli studenti, sia da parte di molti neolaureati in discipline scientifiche, in particolare in ingegneria informatica, ingegneria gestionale, matematica e fisica”.
Perché l’ICT Day è un appuntamento strategico per un gruppo come Maps?
“Perché da tempo abbiamo scelto di valorizzare il rapporto con l’università. Riteniamo infatti che esistano ampi margini di collaborazione tra un settore come il nostro, che richiede un alto tasso di competenze specialistiche, e le facoltà universitarie. Per studenti e neolaureati è fondamentale conoscere le possibilità di impiego che offre loro un’impresa come la nostra e, allo stesso tempo, credo sia importante per loro sapere quali figure sono più richieste sul mercato. Ma le possibilità di collaborazione aprono scenari interessanti anche per i docenti e le stesse facoltà che, per esempio, possono essere interessate a una nostra partecipazione attiva nei progetti di ricerca più innovativi”.
In base a quali elementi puoi dire che questa edizione dell’ICT Day è stata un successo?
“Innanzitutto per la dinamica di svolgimento dell’evento. Come detto abbiamo registrato un’affluenza notevole ma l’organizzazione della giornata e la disposizione logistica degli stand hanno permesso di confrontarci in modo approfondito sia con gli studenti sia con i docenti. Ci sono state molte occasioni di scambio vero, non solo di curricula ma anche di informazioni e punti di vista su aspetti specifici del mondo della ricerca e del lavoro. A conferma di tutto ciò posso dire che, ancora in questi giorni, stiamo ricevendo molte candidature interessanti, peraltro con profili estremamente qualificati”.
Cosa potresti consigliare a chi pensa di candidarsi per entrare a far parte del Gruppo Maps?
“Le competenze sono imprescindibili. Il 95% delle figure impiegate in azienda è in possesso almeno della laurea: in un settore come il nostro la laurea, in particolar modo quella scientifica, è fondamentale. Posso invece dire che non è sempre vero che sia necessaria una specializzazione in ingegneria informatica, per molte delle nostre posizioni spesso cerchiamo figure con lauree in discipline matematiche o fisiche perché, per forma mentis, hanno particolari attitudini per il nostro settore. Contano molto anche altri skills: dalla conoscenza della lingua inglese alla capacità di lavorare in team, fino all’attitudine ad affrontare progetti innovativi nei quali il percorso di lavoro è da costruire più che da seguire”.
[dropcap3]N[/dropcap3]omen omen, possiamo dire senza dubbio in questo caso. O, per farla più semplice: basta la parola! La lingua inglese ci mette di fronte a termini particolarmente concisi e tuttavia espressivi, capaci di mettere immediatamente a fuoco il punto del discorso nella sua luce più rappresentativa. Questo è il caso dell’accostamento di due parole all’apparenza estranee: il sostantivo data (nel senso di elemento, parte costituente) e l’aggettivo open (aperto, senza barriere né limitazioni) che insieme definiscono gli Open Data, termine che anche il legislatore italiano ha definito formalmente nel 2012, inserendolo all’interno del Codice dell’Amministrazione Digitale.
Eppure, anche se aperti, questi stessi dati debbono possedere alcuni requisiti per essere tali, ovvero:
- [highlight]la disponibilità[/highlight] secondo le concessioni di una licenza che ne consenta l’uso da parte di chiunque, anche per utilizzarli commercialmente;
- [highlight]l’accessibilità e interoperatività[/highlight] attraverso le varie tecnologie, comprese le reti telematiche pubbliche e private.
Dal punto di vista storico – perché non sembra, ma questi dati vengono da lontano – possiamo dire che vi sono dei precursori, come ad esempio:
- [highlight]il fenomeno dell’Open Content[/highlight] che si occupa sia di opere creative che di ingegno e ricerca;
- [highlight]l’Open Source[/highlight] che promuove la diffusione e il riuso di software, mediante la condivisione del codice sorgente, per creare nuovi prodotti a partire dal lavoro fatto da comunità di sviluppatori.
E anche se la classificazione in cui gli Open Data trovano la propria ragion d’essere è comune, si tratta in realtà di dati che hanno possibilità di “apertura” diverse. Non solo, ma hanno anche prospettive e ruoli da assolvere differenti, in base alla titolarità dei dati.
Per riassumere le loro caratteristiche possiamo dunque riferirci a una definizione largamente condivisa: “I dati aperti sono dati che possono essere liberamente utilizzati, riutilizzati e ridistribuiti da chiunque, soggetti eventualmente alla necessità di citarne la fonte e di condividerli con lo stesso tipo di licenza con cui sono stati originariamente rilasciati.”
E se pensiamo all’attuale società definitivamente globalizzata in cui accessibilità, interattività e intelligibilità sono gli ingredienti basilari della comunicazione, allora non possiamo che riflettere sulle insostituibili opportunità che si dispiegano intorno a questi dati aperti, capaci di trascinare con sé un elevatissimo potenziale di innovazione e trasformazione nel significato più profondo di queste parole.
Per il settore pubblico, ad esempio, investire sulla trasparenza, l’accessibilità e la fruibilità di dati gratuiti comporta un investimento etico e positivo in una società civile che voglia attuare i requisiti fondamentali della democraticità e della partecipazione.
Allo stesso modo, nel settore privato e naturalmente votato al business, è altrettanto facilmente percepibile come – al di là di eventuali costi iniziali sostenuti per creare o trattare una propria “base di dati” – uno scambio alla pari con altre realtà imprenditoriali che mettano a loro volta a disposizione i frutti del proprio valore, vuol dire investire sì a fondo perduto o quasi sul proprio prodotto, ma anche ritrovarsi nel frattempo migliaia di altrui prodotti o strumenti open o free con cui dialogare e magari implementare le proprie stessi merci. Lo stesso può valere per le ricerche scientifiche e in pressoché ogni settore dell’umana conoscenza.
Si tratta quindi di una sorta di mercato libero transnazionale e interdisciplinare cui attingere in maniera pressoché illimitata, magari dopo aver apportato il proprio contributo di sapere.
Così, in un mondo ormai del tutto connesso, gli Open Data, un passo dopo l’altro, sono in grado, dialogando tra loro, di intersecare ogni aspetto della società con lo scopo di migliorarne, prevederne e innovarne le prestazioni. Dai così aperti e lungimiranti, insomma, da pensare a chi verrà dopo di sé.
Per chi fosse interessato ad approfondimenti su tema, di seguito alcuni siti utili e pertinenti, riguardanti alcuni esempi di banche di Open Data online e Associazioni ed Enti che se ne occupano a livello internazionale.
[boxed_content type=”whitestroke” custom_bg_colour=”#e0e0e0″ custom_text_colour=”#000000″ pb_margin_bottom=”yes” width=”1/1″ el_position=”first last”]
Siti internazionali
[highlight]Open Data Handbook[/highlight]
Un vero e proprio “manuale” sugli Open Data e il loro uso.
http://opendatahandbook.org
[highlight]Open Data Foundation[/highlight]
Organizzazione no-profit dedicata all’adozione di standard di metadati globali e allo sviluppo di soluzioni open-source che promuovono l’utilizzo di dati statistici.
http://www.opendatafoundation.org
[highlight]School of Data[/highlight]
Scuola di dati internazionale con la finalità di potenziare i professionisti e le organizzazioni della società civile attraverso la diffusione delle competenze necessarie per utilizzare i dati.
http://schoolofdata.org
[highlight]Open Knowledge Blog[/highlight]
Blog che, grazie all’apporto di persone appassionate di Open Data e legalità, mettono a disposizione ulteriori temi di approfondimento e discussione.
http://blog.okfn.org/
Siti istituzionali
[highlight]Data.Gov.Uk[/highlight]
Sito del governo inglese che raccoglie richieste di dati su settori diversi dello Stato, come la sanità, la scuola e la cultura anglosassone, creando sezioni di approfondimento e discussione (ad esempio blog).
www.data.gov.uk
[highlight]Data.Gouv.Fr[/highlight]
Piattaforma che permette agli enti pubblici francesi di inserire dati pubblici per produrre informazioni d’interesse generale per la società francese.
www.data.gouv.fr
[highlight]Digital Agenda for Europe[/highlight]
Portale promosso dalla Commissione Europea che ha dato vita a portali sugli Open Data in Europa, tra i quali figurano quello per l’Italia (Regione Piemonte), la Francia, l’Inghilterra e l’Olanda, promuovendo la diffusione dei dati pubblici.
http://ec.europa.eu/digital-agenda/en/open-data-portals
Siti locali
[highlight]Agenzia per l’Italia Digitale – Agenda Digitale Italiana[/highlight]
Sito del Governo italiano volto a perseguire le politiche di Open Data nell’ambito della Open Government Partnership, promuovendo la cultura della trasparenza nella pubblica amministrazione.
http://www.agid.gov.it/agenda-digitale/open-data
[highlight]Dati Piemonte[/highlight]
Portale promosso dalla regione Piemonte che si rivolge a tutti gli operatori pubblici, privati o commerciali, e mette a disposizioni i dati delle PA locali in ambito istituzionale.
www.dati.piemonte.it
[highlight]DatiOpen.it[/highlight]
Portale italiano degli Open Data che persegue ideali di trasparenza, mettendo a disposizione più di 1700 dati organizzati tematicamente e suddivisi per categoria.
http://www.datiopen.it/it/opendata-per-tematica
[highlight]Portale Dati aperti del Comune di Matera[/highlight]
Il portale contiene una serie di dati aperti, rendendo possibile una “radiografia” del comune di Matera e mettendo a disposizione informazioni che riguardano la popolazione nonché le iniziative e le attività promosse dal comune.
http://dati.comune.matera.it
[highlight]Portale Linea Amica[/highlight]
Portale che mette a disposizione tutte le FAQ che di frequente vengono fatte agli URP (uffici relazioni con il pubblico) degli enti aderenti al Network, ai servizi online della PA e agli indirizzi dei principali enti pubblici italiani.
http://www.lineaamica.gov.it/opendata
[/boxed_content]
[dropcap3]D[/dropcap3]opo un rapido sguardo alle principali definizioni e caratteristiche che riguardano gli Open Data, viste in precedenza, ci occupiamo ora in dettaglio di alcune delle loro peculiarità più rilevanti, quelle capaci di renderli così speciali.
Innanzitutto, è esemplare la capacità degli Open Data di dialogare liberamente non solo tra di loro, ma contemporaneamente anche con l’ambiente a loro esterno, fornendo informazioni spesso fondamentali e divenendo allo stesso tempo più facilmente “visibili”. Tutto ciò è reso possibile dall’assenza di ogni forma di barriera al loro utilizzo, a parte quelle prettamente “tecniche” connesse alla conoscenza – o meno – dei codici attraverso i quali gli Open Data e i Dati in genere sono organizzati e strutturati.
L’accessibilità riguarda quindi non solo i dati in sé, ma anche i sistemi di raccolta, stoccaggio e lavorazione con i quali vengono genericamente trattati, al punto da rendere gli Open Data pienamente disponibili, ossia portatori naturali di un ulteriore valore pressoché inesauribile, quello della loro interoperabilità.
E se “l’interoperabilità è la capacità di diversi sistemi e organizzazioni di lavorare insieme (…) di combinare una base di dati con altre” come viene definito nel Manuale degli Open Data, siamo allora in presenza di un requisito essenziale affinché sistemi differenti, lavorando insieme, riescano a fondersi in strumenti di elaborazione di dati sempre più complessi.
L’interoperabilità è dunque “la chiave per realizzare il principale vantaggio pratico dell’apertura: aumentare in modo esponenziale la possibilità di combinare diverse basi di dati e quindi sviluppare nuovi e migliori prodotti e servizi”.
Di fronte a questa vocazione globale tipica degli Open Data, sostenuta dal ruolo di grimaldello operativo svolto dalla lingua inglese e dalla possibilità pressoché infinita di connessione online, è difficile concepire limiti al loro uso, riuso, ricombinazione e ibridazione, se non quelli propri della nostra immaginazione.
Un caso esemplare e per certi versi sorprendente di combinazione tra dati sedimentati nel tempo con flussi di dati in real time, resa possibile grazie a un impiego sincronico di dataset diversi in chiave Open, è quello rappresentato dal sito www.FlyOnTime.us.*
Realizzato tutto in ambiente open, il sistema di elaborazione di dati alla sua base consente al visitatore – tra le altre cose – di verificare personalmente e in tempo reale la percentuale di probabile ritardo dei voli in un dato Aeroporto, in base alle condizioni climatiche previste.
Il processo, infatti, combina insieme i dati storici sui ritardi resi disponibili dal Transportation Bureau con le informazioni meteorologiche concesse dalla Federal Aviation Administration, i bollettini meteo pregressi della National Oceanic and Administration e i dati in real time rilasciati del National Weather Service. Il viaggiatore comune non deve fare altro che connettersi al sito, compilare i campi proposti e ottenere immediatamente e gratuitamente la stima dell’eventuale ritardo!
E dopo questa ulteriore incursione nel mondo open, state pronti ai prossimi articoli: sono in arrivo altri esempi concreti sull’uso e riuso degli Open Data, oltre a qualche “volo fantastico”, stavolta tutto nostro: stay tuned!
[boxed_content type=”whitestroke” custom_bg_colour=”#e0e0e0″ custom_text_colour=”#000000″ pb_margin_bottom=”yes” width=”1/1″ el_position=”first last”]
[*] Mayer-Schönberger Viktor – Cukier Kenneth, “Big Data. Una rivoluzione che trasformerà il nostro modo di vivere e già minaccia la nostra libertà”. Garzanti, Milano, 2013
[/boxed_content]
[dropcap3]S[/dropcap3]piare dal buco della serratura non va più di moda. Oggi basta un qualsiasi ipad per curiosare in tutta tranquillità nella vita di chiunque vogliamo, o quasi. E ad essere analizzati non sono solo i semplici “fatti altrui”, ma qualcosa di più: con l’avvento dei social e degli strumenti che li aggregano e analizzano possiamo scoprire con facilità anche i gusti, le inclinazioni e le avversioni dei profili seguiti. In una parola sola, i loro sentimenti.
Niente di male, abbastanza di buono, molto di divertente e un po’ – ma solo un po’ – di ossessivo.
C’è però un’altra faccia della medaglia, probabilmente un’emoticon: allo stesso modo con cui noi “curiosiamo” nei profili e nelle conversazioni altrui, anche gli altri possono fare lo stesso nei nostri confronti, alla ricerca di quello che di noi li attira o magari li irrita. E, come se non bastasse, tutti noi finiamo nelle maglie più o meno strette di strumenti dai nomi seduttivi (MediaMiser, NUVI, Social Intelligence, Collective Intellect) che in realtà ci scansionano letteralmente dalla testa ai piedi e lo fanno, come si dice, in real time.
Si parla non a caso di programmi che analizzano il sentiment, ovvero le caratteristiche connotative, e non solo denotative, delle conversazioni online, schedandole e marcandole secondo criteri di giudizio che riguardano eventuali espressioni non solo di positività e negatività, ma anche di frequenza e ricorrenza. Il tutto suddiviso o suddivisibile per aree geografiche, lingue di appartenenza, età… insomma tutto ciò che riguarda il “dire, fare, baciare, lettera e testamento”!
E visto che questi programmi si fanno, come dire, i fatti nostri, allora è il caso di rendere loro la pariglia e cercare di svelare qualche loro segreto, così da giocare più o meno ad armi pari.
Vediamo quindi più in dettaglio come avviene questa analisi del sentiment da parte di tali strumenti, cercando di tradurla in un linguaggio più “umano” di quello che utilizzano questi programmi per funzionare.
Intanto un concetto importante: un viaggio nei dati in real time è un viaggio che inevitabilmente ci porta nel futuro a partire sia da quello che è accaduto prima che da ciò che accade nel frattempo. Tutto il flusso di dati, infatti, viene analizzato mentre avanza nel tempo.
Tale processo, che tecnicamente è piuttosto articolato, può essere sintetizzato nei seguenti passaggi:
- le informazioni vengono innanzitutto acquisite attraverso pagine html, post, like, immagini etc;
- i dati così raccolti vengono “puliti” mantenendo solo ciò che è rilevante in termini di contenuto informativo, eliminando ad esempio i messaggi pubblicitari;
- questo flusso ancora grezzo viene filtrato ulteriormente, scartando quei contenuti che non sono significativi per la tematica che si sta analizzando o per il brand monitorato;
- il materiale così selezionato viene analizzato semanticamente (attribuendovi cioè un valore in termine di significato) e vengono messi in evidenza alcuni dei messaggi pertinenti che vi sono presenti: keyword, argomenti, nomi di persone, nomi di brand, luoghi etc;
- tale mole di dati, filtrata e categorizzata, viene analizzata in tempo reale al fine di rilasciare i relativi report (analitici o sintetici) che ne individuano il valore e il sentiment, appunto;
- il tutto attivando – se richiesto – appositi alert nel caso vengano citate parole o situazioni identificati in precedenza come rilevanti, sia in positivo che in negativo.
Alla fine di questo complesso processo di lavorazione i dati vengono rilasciati all’utente attraverso un’interfaccia semplice da consultare, così da condividerne sia i valori che i vari trend risultanti.
Quelli che erano insomma atti comunicativi singoli e differenti, espressi in luoghi e momenti anche diversi tra loro, vengono prima selezionati e infine raggruppati secondo veri e propri percorsi di senso e quindi di valutazione. E probabilmente ben al di là delle intenzioni iniziali degli emittenti, o per lo meno della loro consapevolezza.
Come dire: attenzione a ciò che scriviamo, filmiamo e commentiamo online! Qualcuno, prima o poi, ci renderà pan per focaccia, fossero anche solo i sistemi di re-marketing, in grado di inseguire i nostri passi di consumatori per deliziarci di offerte e opportunità sempre più convenienti. O il politico di turno, che vuole sapere cosa ne pensa di lui l’opinione pubblica. O ancora un celebre cantante che cerca di promuovere la sua musica in rete con maggiore efficacia…
E se qualcuno ha dei dubbi sull’efficacia di tali strumenti, cambierà facilmente idea guardando questo grafico, realizzato “spiando” un singolo profilo di twitter in modo da scoprire i suoi interessi:
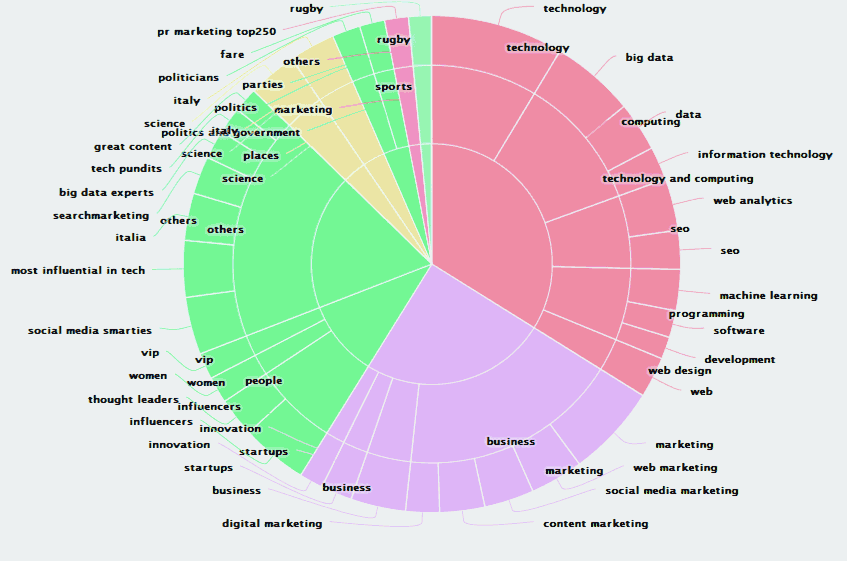
Alla rete, insomma, non la si fa. Meglio dedicarsi, come vuole la migliore tradizione, a “seminare” il proprio marito o la propria moglie!
[dropcap3]G[/dropcap3]enerare asset digitali è senza dubbio un’impresa complessa, ma per motivi diversi da quelli che si possono immaginare comunemente.
Il problema della loro creazione, infatti, non sta tanto nelle difficoltà di tipo operativo o strumentale che si possono incontrare nella loro generazione: il primo ostacolo sta piuttosto nella capacità, a monte, di intravederne o meno l’esistenza.
I dati rilevanti da cui iniziare questo processo sono infatti occultati o sommersi da altri dati, per lo più insignificanti, che vengono raccolti sotto forma di segni, stringhe di testo, numeri e codici vari.
Privi di qualunque connotazione, questi dati si comportano come veri e propri rifiuti informazionali e scarti di altre comunicazioni, del tutto sterili.
Tutto però cambia quando un’intuizione, un progetto o una visione accende all’improvviso il loro potenziale e – come un pifferaio magico che guida una fila sterminata di topolini ben disciplinati – li conduce non alla fine di un precipizio, ma all’origine di una nuova strada da percorrere insieme.
La meta comune è la ricerca di un vantaggio aggiunto e possibilmente inedito, che li faccia diventare appunto “rilevanti”.
Non usciamo da questo paragone un po’ fantasioso, ma entriamo piuttosto nei meandri specifici di questo approccio, seguendo anche noi il suono di un flauto immaginario.
Occorre innanzitutto ricordare che un asset, di qualunque tipo sia, è definibile come tale soltanto se crea valore. L’obiettivo è dunque quello di generare “ricchezza” in senso lato, che può essere intesa sia nelle sue declinazioni più concrete e tangibili, tradotte in business, che nelle sue accezioni più astratte, quali il benessere sociale, il progresso, l’aumento della consapevolezza etc.
In questo articolo ci occupiamo della prima eventualità, quella che porta alla creazione di ricchezza economica, mentre approfondiremo in un’altra occasione i valori più immateriali, ma non meno importanti, che questi stessi asset digitali possono accrescere o creare.
Ragionando in termini prettamente economici, dunque, cercando di definirne meglio il campo d’azione, un asset digitale di business si può dire tale se:
- [highlight]permette la creazione di una nuova fonte di ricavi[/highlight] o l’aumento degli stessi, anche consentendo la riduzione dei costi di un determinato business;
- [highlight]crea un elemento di unicità nella propria offerta di valore[/highlight], aprendo nuovi orizzonti di mercato.
Ragionando invece dal punto di vista operativo e metodologico, una delle “ricette” più efficaci per creare effettivo valore sta senz’altro nel combinare dati che provengono da fonti diverse e metterli in correlazione. Il fine ultimo è quello di creare nuove informazioni originali e possibilmente esclusive.
Una delle opportunità di business più interessanti di questo tipo è senz’altro quella di creare valore attraverso l’uso di dati accessibili e pubblici combinati con altri di tipo esclusivo e proprietario. È la promessa degli Open Data, resi disponibili da soggetti pubblici o privati che possono essere a loro volta combinati sia con algoritmi che con altri dati, entrambi esclusivi, per generare insieme nuovi asset digitali.
Un esempio particolarmente significativo di creazione di asset digitali a partire dagli open data è l’esperienza nata negli Stati Uniti che ha reso pubbliche le informazioni sulle condizioni meteo. Questa semplice “apertura” ha permesso a circa 400 imprese di sviluppare una propria offerta di servizi, con un giro d’affari tra i 400 e i 700 Milioni di USD, e di dare lavoro a circa 4.000 persone. Un altro esempio di asset digitali, anch’esso innovativo, è quello realizzato da IBM e riportato in questo articolo. In questo caso IBM ha creato un asset digitale combinando due fonti di dati: la prima, esclusiva, rappresentata dai vari modelli linguistici e psicologici, la seconda, pubblica, composta dai tweet del soggetto che viene classificato dalla piattaforma/sistema.
Due esemplificazioni emblematiche di come una “fila” sterminata di dati, assemblata, guidata e condotta per bene, può raggiungere nuove frontiere di utilizzo e generare valore di business in grado a sua volta, un giorno, di rifornire di Dati il prossimo pifferaio magico. A suon di musica, chiaro!
[dropcap3]P[/dropcap3]arlando di Dati e delle diverse tecnologie che li trattano, è sempre più evidente come la capacità di leggerli, analizzarli e interpretarli sia in primo piano, rispetto alle tecniche pur innovative utilizzate nei processi della loro elaborazione. Il passaggio cruciale è quello che va dai Big Data – definiti semplicisticamente dall’occorrenza di quattro variabili, ovvero volume, varietà, velocità e veridicità – fino ai Relevant Data, dati portatori di particolare interesse e valore. La materia prima non manca, anzi “deborda” in pressoché tutti gli ambiti.
I fiumi di dati generati negli ultimi decenni hanno prodotto giacimenti di informazioni riguardanti ogni attività, umana e non, tanto preziosi quanto spesso trascurati, sottovalutati e incompresi: si tratta di un potenziale di altissimo valore che si dispiega unicamente quando viene tradotto in informazioni utili.
E nonostante le imprese, le aziende e gli enti pubblici siano depositari di enormi riserve “auree” di dati, acquisiti grazie a sistemi di IT automatizzati ormai comunemente utilizzati, un tale diluvio di informazioni rischia di offuscare la potenziale qualità insita in tale sovrabbondanza.
Per tutelarsi dalla perdita di tali potenziali significati occorre agire sul processo di interpretazione di questi volumi di “anonimi” dati, mitigandone il rumore di fondo in modo da reperire e tracciare informazioni selezionate cui poter attingere, magari con nuovi automatismi utili a produrre benefici e utilità varie.
L’attuale processo innovativo sta proprio nello sviluppo di prodotti dedicati ai dati rilevanti che, attraverso soluzioni tecnologiche di ultima generazione, siano in grado di riconoscerli in quanto tali, trasformarli e metterli a sistema, al servizio di necessità peculiari.
È possibile descrivere la filiera di trasformazione dei Big Data in Relevant Data in un processo costituito da quattro fasi:
- [highlight]Feed[/highlight](acquisizione): è la fase in cui il dato grezzo, proveniente da sensori o da altri sistemi software, viene acquisito dal sistema e trasformato per renderlo il più possibile omogeneo.
- [highlight]Enrich[/highlight] (arricchimento): i dati acquisiti dalla fase precedente possono essere arricchiti, dal punto di vista semantico, per cercare di attribuire loro un significato. Le operazioni che vengono svolte in questa fase sono quelle di: estrazione di concetti, classificazione di documenti, annotazione semantica (identificazione di entità, disambiguazione).
- [highlight]Relate [/highlight](comprensione): in questa fase ci si occupa di identificare e validare dei fatti o degli eventi, trovare delle correlazioni ed eseguire quindi delle azioni di aggregazione tra dati omogenei.
- [highlight]Evaluate [/highlight](decisione): il risultato delle fasi precedenti viene messo a disposizione dei “decisori” (che possono essere altri software o persone). Possibili operazioni che vengono svolte in questa fase: ricerca in un archivio di eventi o fatti, produzione di flussi real time di eventi o fatti, cruscotti analitici, sistemi di alert…
Questo processo a step successivi rende i dati di partenza non solo visibili e leggibili, ma capaci di generare nuove informazioni di senso e nuovi significati, finalmente utili per le varie finalità attribuite in fase di progettazione.
Per fare qualche esempio concreto possiamo parlare di alcuni sistemi di ricerca che apprendono qualcosa di noi e delle nostre necessità osservando il nostro comportamento all’interno dei siti che consultiamo.
Questi algoritmi unfatti, grazie alla capacità di analizzare e contestualizzare le scelte da noi fatte in precedenza, ci mostrano in tempo reale altri risultati attinenti a ciò che stavamo cercando, facendoci risparmiare tempo con suggerimenti appropriati.
E’ il caso ad esempio del sito Walmart che, dopo aver inserito sul proprio sito di e-commerce un motore di ricerca con queste caratteristiche, ha aumentato del 15% le proprie vendite online.
O anche di FedEx, che ha implementato un sistema di supporto alle decisioni in grado di suggerire i percorsi ottimali per la sua filiera logistica con l’obiettivo di far arrivare le merci nei tempi previsti e con costi sempre più bassi.
I dati che vengono presi in considerazione per questo fine sono molteplici: la posizione dei mezzi, le condizioni e previsioni meteo, le condizioni del traffico e così via.
Le decisioni su come le merci devono proseguire nel loro percorso vengono prese in tempo reale, e questo permette di ridurre l’impatto negativo che eventuali e imprevisti accadimenti esterni possono avere sull’azienda stessa e la sua organizzazione.
I risultati sono stati straordinari e in breve tempo l’investimento si è abbondantemente ripagato (430% di ROI).
Tutti esempi decisamente concreti e positivi, dunque, che confermano come i Big Data, trasformati in Relevant Data, non solo sono in grado di generare utilità in senso assoluto, ma sono capaci di produrre valori di business vero e proprio.
Per vedere in maniera approfondita come si generano asset digitali di business, vi rimandiamo a un altro articolo. A presto!
[dropcap3]N[/dropcap3]on è noto se l’immortalità del corpo umano sia una condizione prima o poi realizzabile: tutte le forme biologiche sono soggette a limiti intrinsechi che potranno forse essere superati in un futuro attraverso interventi di natura medica o ingegneristica.
Le parole del noto oncologo italiano Umberto Veronesi non lasciano tuttavia spazio a fraintendimenti: “Vive a lungo e felice chi non smette di amare, di pensare e di agire”. Niente intrugli, dunque, o segreti celati da rompicapi irrisolvibili… il seme della felicità non sta tanto nell’immortalità quanto nel buon senso di chi, nella sua vita, ha esplorato anche gli abissi più profondi della malattia e ne è riemerso con un respiro più ampio. E tuttavia le regole, in questo caso, non sono uguali per tutti. Anzi, non potrebbero essere più diverse. Ogni forma di vita ha le sue, che si traducono in una precisa misura di tempo a propria disposizione.
Uno di questi esseri, il più mastodontico del pianeta – e scopriremo non a caso – ha ispirato artisti e letterati. Parliamo proprio di lei, la BALENA, animale maiuscolo in ogni sua parte, dalla testa alla coda. Questa creatura maestosa, quasi mitologica, nasconde più di un segreto proprio in termini di longevità, uno dei quali non poteva sfuggire a uno dei suoi più grandi estimatori: “… il capodoglio non respira che un settimo, o una domenica, di tutto il suo tempo” dice non a caso Herman Melville nelle pagine immortali di “Moby Dick”. In queste poche righe è condensata una vera e propria strategia di sopravvivenza, oltre che un patrimonio inestimabile di dati scientifici ancora da scoprire ed esplorare.

Un eccezionale esempio di persistenza della vita attraverso il tempo lo dà in particolare la Balena artica (Balaena mysticetus), un enorme animale di colore scuro che può raggiungere i 21 metri di lunghezza e un peso massimo stimato di 152 tonnellate, in grado di vivere oltre i 200 anni in ottima salute, grazie alla bassa incidenza di malattie nella sua specie.
Respiratrici “consapevoli”, le balene devono decidere quando respirare e lo fanno sfruttando con intelligenza istintiva ciò che è a loro disposizione. Così trattengono il respiro per lunghi periodi grazie a polmoni capaci, scambiano notevoli quantità di aria tra inspirazioni ed espirazioni, distribuiscono l’ossigeno alle parti del corpo che più lo necessitano, tollerano meglio ciò che potrebbe danneggiarle, ovvero il biossido di carbonio. Respiratrici doppiamente consapevoli: dormono certo, come tutti i mammiferi, ma non possono restare incoscienti troppo a lungo proprio per poter respirare e risolvono il problema mettendo a riposo solo un emisfero del loro cervello per volta, restando sempre vigili.
Ecco allora che, seppure declinato in una eccezionale sapienza di specie, il segreto della balena può rivelarsi un esempio universale della necessità per tutte le creature viventi di andare oltre i propri limiti, per rimisurare l’idea stessa di longevità in termini di controllo sull’efficacia dei propri sforzi.
L’esempio della balena ci racconta come la migliore performance possibile per ciascuno è forse quella di saper convertire le risorse disponibili – pur nei loro limiti invalicabili – in un esercizio di consapevolezza ed efficienza, per mettere a frutto appieno la nostra vita come la Natura ci insegna.
Ed ora, prendiamo un bel respiro e mettiamoci alla prova!
[boxed_content type=”whitestroke” custom_bg_colour=”#e0e0e0″ custom_text_colour=”#000000″ pb_margin_bottom=”yes” width=”1/1″ el_position=”first last”]
[highlight] Per saperne di più [/highlight]
– Keane M. et al. Insights into the evolution of longevity from the bowhead whale genome.
– Annalisa Berta et al., Marine Mammals: Evolutionary Biology, 3ª ed, Academic Press [1999], 2006, ISBN 0-12-088552-2.
– Marine Mammal Biology: An Evolutionary Approach, Blackwell Publishing, 2002, ISBN 0-632-05232-5.
– “Cetacei”, Microsoft® Encarta
– Cell Reports.
– Enciclopedia Treccani.
– PiKaia, il portale dell’evoluzione.
[/boxed_content]